服务器监控体系构建实战
本文根据群友分享整理而成。
作者介绍
赵舜东
江湖人称赵班长,曾在武警某部负责指挥自动化的架构和运维工作,2008年退役后一直从事互联网运维工作。
曾带团队负责国内某食品电商的运维工作,也是《saltstack入门与实践》作者之一。
主题简介
我们今天的话题是《中小企业监控体系构建实战》,前期分享了《中小企业自动化部署实战》还没有看到的朋友可以先阅读下,这样也能明白为何要定位中小企业。监控这个话题实在太大,所以本文的正确定位应该是如何构建一个“相对”完善的监控体系。
从面试开始
在之前的招聘面试中,我必问的一个问题就是“你们之前公司的监控体系是怎么做的?你认为怎么做效果比较好?”
经常得到这样类似的答案:“我们公司用的Nagios、Cacti做监控,或者说我们公司用Zabbix做监控”,再继续追问往往得到的也是如何使用这些工具的细节的回答。
这样的回答固然没错,但却反映出来运维人员经常会被工具迷惑双眼,从而忘记了最初的出发点。本文就以一个刚入职的运维工程师小王的故事来阐述监控体系,所以这个故事的名字叫做《小王特烦恼》。
1. 确定目标、统一思想
我们直接跳过什么是监控和监控的重要性等大段描述,先仔细的想一想,监控的目标是什么?
每个人的答案都不同,我的回答是:终极目标就是为了保证业务的持续和稳定运行。如此偏激的回答就是让读者从现在开始要站在业务的角度的开始规划监控体系,而不是某个技术范畴。
注意:本文不涉及性能测试、性能优化中的监控,所有文字的出发点都是日常运维监控。
在开始之前,我们还是先统一下认识:要监控一个对象,需要掌握哪些东西呢?
监控对象的理解:要监控的对象你是否了解呢?比如CPU到底是如何工作的?
监控对象的指标:我们要监控这个东西的什么属性?比如CPU的CPU使用率、负载、上下文切换。
确定报警基准线:怎么样才算是故障,要报警呢?比如CPU的负载到底多少算高?
如果上述的条件不满足,那就先不要开始实施监控了,因为等做完了,你会发现,然并卵?
2. 故事开始
王小明(化名)刚刚毕业,到了一家刚刚起步的电商公司任职:运维工程师,刚上班第一天,小王收到领导安排的光荣任务:把我们公司的监控搞起来!
小王想了好久,没想明白,索性不想了,从手头接触到的慢慢开始吧,于是小王决定先去机房看看。
2.1 硬件监控
到了机房,小王看着公司的各种品牌的服务器,想到的第一件事情就是,这些硬件设备,我要监控起来。
硬件设备监控是最基础的监控手段,比如定期的的机房巡检。
通常我们的服务器上都会有远程控制卡,如Dell的iDRAC,HP的ILO和IBM的IMM等,可以通过Web界面来进行硬件的监控和管理工作,如果购买企业级的授权,还可以使用控制台进行管理。
在Linux下,通常我们使用IPMI来完成物理设备的监控工作。通常必须要监控的就是温度、硬盘故障等。
小王编写了自己职业生涯的第一个脚本,就是使用ipmi工具获取温度传感器的数据,大于50就发一份邮件给他,虽然感觉不高端,但总算是有一个开始。

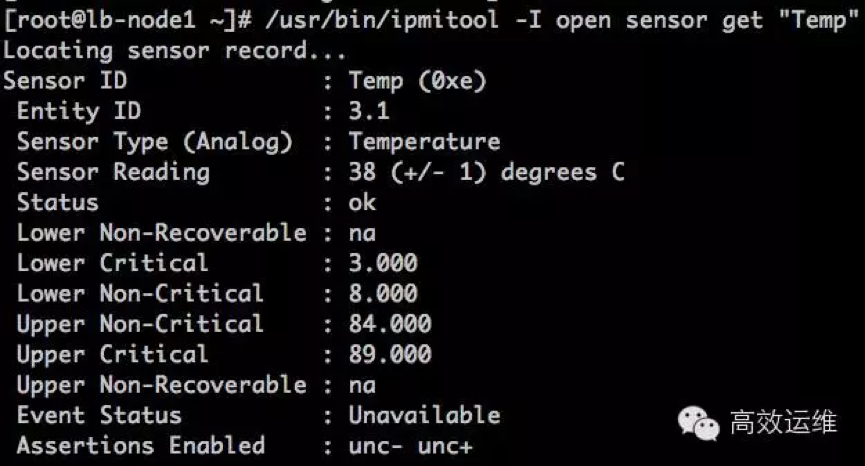
故障回想:之前我司托管在北京某机房的设备就出现过,因为刚好所在机柜区域的空调坏了,导致服务器温度过高,然后系统宕机。
2.2 系统监控
小王下一个想到的就是系统监控,公司全是Linux的服务器,系统资源的使用情况,肯定是要监控起来的。
系统监控是监控体系的基础,系统监控主要的对象有:
- CPU
- Memory
- IO
CPU:关于CPU,有3个重要的概念:上下文切换(context switchs),运行队列(Run queue)和使用率(utilization)。
这也是我们CPU监控的三个重点。通常情况下,每个处理器的运行队列要小于等于3,CPU 利用率中user/system比例维持在70/30,上下文切换要根据系统繁忙程度来综合考量。
常用的监控工具有:top vmstat mpstat
内存:Linux虚拟内存是一个庞大的东东,通常我们需要监控内存的使用率、SWAP使用率、同时可以通过内存的使用率曲线来发现某些服务的内存溢出等。
监控工具有:free vmstat
IO:IO分为磁盘IO和网络IO。除了在做性能调优我们要监控更详细的数据外,那么日常监控,只关注磁盘使用率、io wait即可,网络也是监控网卡流量即可。工具有iostat iotop iftop。
TCP监控:在很多情况下有必要监控TCP的状态,可以使用netstat或者ss来获取所有的TCP连接,来展现11种不同的TCP连接状态的数量,可以在大并发中及时发现TCP的相关故障。
其它的系统监控还有运行的进程数、登陆用户、Open File等。
2.3 应用服务监控
小王把硬件监控和系统监控研究明白后,登陆到服务器上继续研究,偶然间一个ps aux,小王发现,我们服务器上运行了这么多的服务,那都需要监控起来啊。
应用服务监控也是监控体系中比较重要的内容,例如:
- Apache:Apache提供了mod_status和mod_info模块用来输出Apache的状态,小王写了一个脚本,各种grep和awk搞定。
- Nginx:同样有状态模块,编译的时候加上—with-http_stub_status_module,然后就可以使用stub_status on来开启了。
- Memcached:小王使用nc给memcached发送了一个stats命令就获取到了所有想要的信息。
- Redis:小王还是使用nc给redis发送了一个info命令就获取到了redis的相关状态。
- JVM:使用jmconsole,或者jmx就可以进行远程监控。
于是小王,将线上的各种服务,都一个一个的进行了监控,这样这些服务的详细的运行状态就了如指掌了。
同时,还需要将所有的API接口状态进行监控,比如通过curl检查返回的HTTP状态码。有条件的用户,可以做一个URL监控平台,专门用来做这个事情。

2.4 引入Zabbix
自从小王接收到监控的任务后,这Shell编程能力是越来越强了,但是每天一打开邮箱就被各种报警所淹没,脚本多而杂乱。
小王想,我需要一个什么监控工具来干这些事,不能这么写脚本下去了。于是在网上进行各种搜索,发现了很多的监控工具如Nagios、Cacti、Zabbix,原来自己之前费那么大劲,这些工具早就实现了。
经过相关的对比,小王选择了Zabbix。然后之前的所有监控范畴,都可以整合到Zabbix中。
- 硬件监控:Zabbix IPMI Interface
- 系统监控:Zabbix Agent Interface
- Java监控:Zabbix JMX Interface
- 网络设备监控:Zabbix SNMP Interface
- 应用服务监控:Zabbix Agent UserParameter
- MySQL数据库监控:percona-monitoring-plulgins
- URL监控:Zabbix Web 监控
这一下子把之前干的工作全集成到一个平台上了。而且之前编写的所有的应用服务的监控脚本,简单修改就可以使用。
同时也可以灵活的设置报警阈值、告警方式、告警升级、告警去重、告警依赖等等,同时还使用Zabbix的自动发现功能实现上线一台服务器后,自动添加监控。
使用Zabbix Proxy实现了多机房的分布式监控,这简直太棒了。
对于告警通知:邮件、微信、短信、钉钉等,都可以与Zabbix快速的集成,网上有很多此类文档。
同时,针对某些可以进行直接处理的报警,Zabbix可以触发Action来轻松帮你实现,故障的自动处理。
于是小王准备向经理汇报工作,此处省略300字,但是不到10分钟小王垂直头回来了。因为经理问了一个问题,小王回答不上来:小王,今天咱们网站的整体PV是多少?现在访问最多的页面是哪个?
2.5 流量分析
小王首先想到的是把访问日志拿出来各种awk然后sort一下,但是这次他没有急于开始,难道就没有做这些统计和分析的工具吗?
于是小王发现了google分析、百度统计、站长工具等等一堆统计的东西,只需要在页面嵌入一个js即可。
但是呢?这个数据始终是在对方那里,而且功能定制起来也不方便,于是google帮助了他,一个叫做piwik的开源项目映入眼帘。
网站流量分析对于运维人员来说,更是一门必须掌握的知识了。比如对于一家电商公司来说,通过对订单来源的统计和分析,可以了解我们在某个网站上的广告投入有没有收到预期的效果。可以区分不同地区的访问人数、甚至商品交易额等。

而且,流量分析是运维向运营拓展的必经之路,作为一名运维工程师很有必要掌握公司站点的各种访问详情。
2.6 网络监控
作为一个针对全国用户的电商网站,时刻掌握各地到机房的网络状态是小王的下一个监控目标。
网络监控是我们构建监控平台是必须要考虑的,尤其是针对有多个机房的场景,各个机房之间的网络状态,机房和全国各地的网络状态都是我们需要重点关注的对象,那么如何掌握这些状态信息呢?我们需要借助于网络监控工具Smokeping。
Smokeping 是rrdtool的作者Tobi Oetiker的作品,是用Perl写的,主要是监视网络性能,www 服务器性能,dns查询性能等,使用rrdtool绘图,而且支持分布式,直接从多个agent进行数据的汇总。
同时,由于自己监控点比较少,还可以借助很多商业的监控工具,比如监控宝、基调、博瑞等。同时这些服务提供商还可以帮助你监控CDN的状态。

2.7 安全监控
虽然iptables帮助小王完成了四层的安全防护,但是针对七层的Web层面怎么办呢?
于是小王使用Nginx + Lua编写了一个WAF,然后把相关的日志记录到了Elasticsearch中,通过kibana可以图形化的展示不同的攻击类型的统计。
同时小王学习使用python还写了一个爬虫定期扫描github,有没有公司相关的关键字,以免同事分享代码时,不小心涉及到敏感的内容。

(图片来源https://github.com/loveshell/ngx_lua_waf)
2.8 业务监控
小王再去向经理汇报,刚走到门口被总经理碰上了,张总说:小王啊,你们经理汇报你最近监控工作干的不错,你给我说下,咱们现在10点的时候总订单是多少,每分钟平均订单有多少?
小王又蒙了,我自己也曾经就是那个小王!
没有业务指标监控的监控平台是一个不完善的监控平台,通常在我们做监控系统中,必须将我们重要的业务指标进行监控,并设置阈值进行告警通知。
比如每分钟的订单、每分钟注册、日活用户、短信使用量等重要的业务指标都可以加入到Zabbix上。
注:由于业务监控图表,涉及到隐私的数据太多,就不截图了。
2.9 日志监控
通常情况下,系统会产生系统日志、应用程序会有应用的访问日志、错误日志,服务有运行日志等,可以使用ELK来进行日志监控。
对于日志来说,最常见的需求就是收集、存储、查询、展示,开源社区正好有相对应的开源项目:
- logstash(收集)
- elasticsearch(存储+搜索)
- kibana(展示)
我们将这三个组合起来的技术称之为ELK Stack,所以说ELK Stack指的是Elasticsearch、Logstash、Kibana技术栈的结合。
如果收集了错误日志,那么如果部署更新有异常出现,可以立即在kibana上看到。当然也可以使用Zabbix来进行错误日志的过滤来进行告警。

2.10 自动化
经过努力,小王完成从监控菜鸟到头脑中有一个相对完整的监控体系的逆袭,但是在大规模的环境中,如果无法做到自动化监控,那么手动添加监控不仅仅是一个恐怖的工作,而且也无法保证完整性。
自动化的方案有很多,通常有主动和被动不同的形式,这里相对Zabbix来说。
主动形式:
比如使用Zabbix的自动发现,主动的对全网进行扫描,然后自动添加相关的监控服务器和引用监控模板。
被动形式:
也可以使用Zabbix API进行被动的监控的添加。比如以CMDB为核心,如果检测到某服务器增加了Nginx服务,那么自动调用Zabbix API添加上Nginx的监控模板。
真正想做到更完整的监控体系,目前的开源软件,确实无法很好的满足,有条件的公司都开始自己开发自己的监控系统,比如小米开源的Open-Falcon。
也有比较好的开源的监控框架如Sensu等,再加上influxdb grafana可以用来定制符合自己企业的监控平台。
2.11 可视化
经过小王的各种努力,终于一个相对完善的监控平台使用Zabbix构建起来了,小王为此还做一个漂亮的screen,来进行展示,但是有一天突然订单量特别少,张总又一次到了运维部,但失望而归,因为整个监控体系并不能反映出来订单量为什么减少了?
运维的重要目标之一就是数据的可视化,一个监控平台不能很好的反映出来业务的波动,就是耍流氓。之前的一切努力在业务部门的领导中变得一文不值!!!
我们能做的有以下几点:
面向传统运维:
- 尽可能的完善业务监控,如果有专门的业务分析系统,要想办法和运维的监控平台进行结合。
- 梳理清楚各个子系统之间和业务的关系,比如如果突然间流量增加了50M,能够快速的知道这50M流量到了那个业务系统上,访问的哪些URL,以及这个业务系统的相关状态。
面向DevOps:
将所有的监控项和业务之间建立关系树,比如业务、网络、系统、数据库、流量、推广活动(流量分析)之间可以形成一个庞大的关系链。这是一个比较庞大的工程,业务是多变的,如何让监控平台能尽可能的适应多变的业务是一个艰巨的任务。

到面试结束
该结束了,因为我无论怎么努力增加,还是觉得总有漏下的。
监控的话题还有很多很多,比如还有和运维相关的页面性能监控(页面资源数量、DNS解析时间、首屏时间、加载最慢的资源、产生阻塞的JS等)、代码监控、与运维无关的舆论监控等,先这么多吧!
好的,我们是从面试开始引入的监控的话题,那么就从面试结束吧!下次再遇到类似的面试题,我相信读者心里一定有了自己的答案,这里就不在详述,一个相对完善的运维监控体系是否已经在你脑海中形成了呢?
小贴士:面试中,如果你遇到一个有很强的责任心,连洗澡都要带上手机,以免错过报警的人,不要犹豫,先招进来再慢慢培养吧。责任心是运维工程师的第一要素!
后记:小王的故事结束了,小王目前被监控的关系树锻炼的连王菲、李亚鹏的关系都能搞明白了。可是你呢?
如果你是一名运维工程师,动手干吧,监控会是一个不断完善的工程,这就是运维(运营)和项目的本质区别。
如果你是一名Devops,那么开始编程吧!
如果你是一名老板,给公司的运维工程师一个转变的机会和一些时间,人总是不断进步的!
FAQ:
故障自动处理有没有相关的思路?
不同业务形态、不同架构、不同服务可能采用的方式都不同,这个没有一个固定的东西分享。可以参考之前腾讯蓝鲸的分享,他们实现了故障自愈的功能。
运维需要懂业务吗?
我个人的观点是懂业务能让运维走的更远,运维服务的对象不一定是其它部门,为什么不能是终端用户呢?
可以站在终端用户的视角来做运维,比如有用户反映访问慢,为什么慢,是架构的原因,Nginx配置的原因,还是数据库的原因。
不要等着领导来安排,运维能带来的价值是需要运维自己做出来的,思想有多远,运维就能走多远!
那么监控在这里发挥的作用就是:让数据说话!
做监控也需要CMDB吗?
我认为CMDB是基础,尤其是在自动化运维的模式下,你需要有一个地方能准确的提供一台服务器放在哪个位置、配置是什么?什么时候购买的?什么时候过保?都运行了哪些服务、开放了什么端口、版本是什么(升级时使用)。
有了这些数据,就可以轻松和配置管理系统、部署系统、监控系统有效的结合起来。总结起来就是:以业务为导向、以CMDB为中心、以API为基础来进行运维体系的建设。
有了CMDB的数据支撑,那些看着高大上的自动绘出架构图和机柜图就不是难事了。



